In the present world, where terabytes of data are available in digital format, the popularity of databases also started growing. Thus, we require some process for integrating and loading data from different sources for computation and other analysis. ETL in data warehousing served the purpose and started to become the primary method of data processing for projects. A data warehouse system enables an organization to run powerful analytics on huge volumes of historical data in ways that a standard database cannot.
What is ETL?
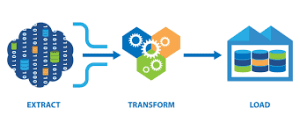
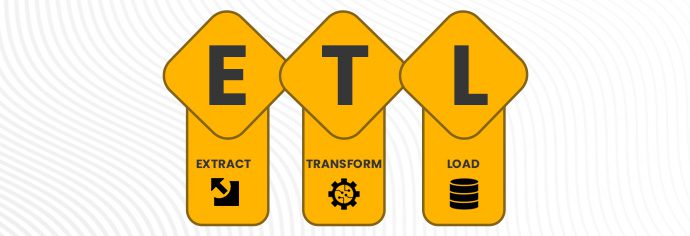
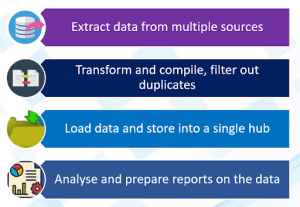
Fig 1: ETL process overview
ETL is the short for Extract, Transform and Load. It is a data integration process that combines data from different data sources into a single consistent data store that is loaded to a data warehouse or target system. ETL is a recurring method and the frequency of running ETL depends on the frequency at which the source data gets updated.
ETL provides the foundation for data analytics and machine learning workstreams. Through a series of business rules, ETL cleanses and organizes data in a way such that it meets the business intelligence needs, like monthly reporting, but it can also tackle more advanced analytics, which can improve back-end processes or end user experiences. ETL is often used by an organization to:
- Extract data from legacy systems
- Cleanse the data to improve data quality and establish consistency
- Load data into a target database
How ETL in Data Warehousing Works?
As understood from the abbreviation, ETL process consists of three stages:
- Extraction
- Transformation
- Loading
Extraction
Extraction is the process of extracting data from the different data sources for further use in the data warehouse process. Here the raw data is copied and exported to a temporary place such as a staging database. This is also one of most time-consuming stages in the ETL pipeline. The data sources can be both structured and unstructured and some of the sources include:
- Excel files
- SQL or NoSQL servers
- CRM and ERP files
- Web pages
Transformation
Transformation is the process of transforming the raw data from whatever format it is available into data warehousing format. After changing the structure of data, some data cleaning and validation activities are also done in this stage. Some of the common tasks in this stage include:
- Filtering, cleansing, de-duplicating, validating, and authenticating the data
- Changing the column headers
- Summarizing the data such as calculating the sum or count against some parameters
- Translating the data present in column for maintaining consistency within the data warehouse
- Performing validation to ensure data quality and compliance
Loading
Loading is the final stage of the ETL process. It involves migrating transformed data from the staging area to the target data warehouse. It can be carried in two ways: Update & Refresh.
In most cases, the Update method is used. In this method, you initially load the entire data to the data warehouse (one-time activity) and then periodically load the incremental data changes. In fewer cases the refresh method is preferred. Here, it is required to erase and replace the entire data in the data warehouse. This depends on the business use case and the nature of the raw data.
Use cases of ETL in Data Warehousing
ETL is a widely used activity to load data present in different data sources to the main data warehouse. One of the projects in TA, used the ETL job that runs periodically to migrate the data from different SQL server databases to the main data warehouse. This process is automated and runs at a scheduled time every day. A master table is maintained which consists of the list of databases and the tables to be migrated from them. The database credentials are encrypted and stored in a different table. Also, a job is created to update the credentials, if required. The data from the data warehouse was then used to generate reports using tools such as Power BI and Tableau. Having all data in a data warehouse helps to simplify the data connection and also set the relationship among tables in reporting tools.
Secondly, for a Open Data Cube project, ETL was used to load geospatial data from different earth observation satellites and store it in a data warehouse. Here incremental update of data was done and the ETL job is manually triggered. This job is run manually whenever new satellite images are released. ETL is developed in python and the ETL inputs include the latitude and longitude range and also the date span for which data is to be ingested. If the data is already existing in the DB, it is skipped and else the new data is inserted. The frequency of the ETL here depends on the frequency of the satellites considered. The resultant data in the data warehouse tables are used to conduct geospatial studies in Python.
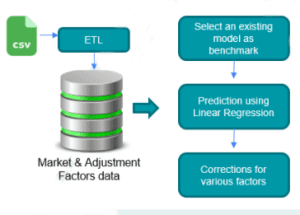
Also, for a sales estimation project to forecast the car sales, ETL was important to extract and consolidate the data. The project had data present in different formats such as Excel/CSV files, data from an external API, Snowflake etc. ETL thus played a crucial role in extracting the data from all these sources, transforming, cleaning and validating the data and finally migrating the valid data to data warehouse tables. Python is used again to develop the ETL pipeline. Each of the source files have different update frequency and hence a configuration file is maintained and updated manually. This file contains information whether a particular data in the data warehouse should be updated or not. The ETL is triggered manually and based on this configuration file, it understands what all data should be updated, and the remaining are skipped, that is the existing data is maintained. Here for some tables, data is incrementally updated and for others, the DB is cleared, and the new data is inserted. The data from data warehouse tables was then used by the Django application to forecast car sales.
Conclusion
ETL is a powerful technique in data engineering to extract and process the data. ETL solutions improve data quality by performing data cleansing prior to loading the data to a different repository. This data can then be used for calculations, generating visualizations etc. Being a time-consuming operation, ETL is recommended more often for creating smaller target data repositories requiring less frequent updation. ELT (extract, load, transform), another technique similar to ETL is more preferred when working with increasingly larger volumes of data that changes or real-time data streams.
Ready to turn your idea into a powerful digital solution?
Partner with our experts to design, build, and scale technology tailored to your business goals.
Contact us Today